

|
Getting your Trinity Audio player ready...
|
Study shows the strongest results when consumer GPU clusters complement enterprise-grade GPUs – delivering comparable compute power at a fraction of the cost.
Delaware, US | 24th November 2025 | A peer-reviewed study by io.net has confirmed that consumer GPUs, such as Nvidia’s RTX 4090, can play a pivotal role in scaling large language model (LLM) inference. The paper, Idle Consumer GPUs as a Complement to Enterprise Hardware for LLM Inference, was accepted by the 6th International Artificial Intelligence and Blockchain Conference (AIBC 2025) and provides the first open benchmarks of heterogeneous GPU clusters deployed on io.net’s decentralized cloud.
The analysis finds that RTX 4090 clusters can deliver 62–78% of enterprise H100 throughput at approximately half the cost, with token costs up to 75% lower for batch or latency-tolerant workloads. The study also shows that while H100s remain 3.1× more energy-efficient per token, leveraging idle consumer GPUs can reduce embodied carbon emissions by extending hardware lifetimes and tapping renewable-rich grids.
Aline Almeida, Head of Research at IOG Foundation and Lead Author of the study, said “Our findings demonstrate that hybrid routing across enterprise and consumer GPUs offers a pragmatic balance between performance, cost and sustainability. Rather than a binary choice, heterogeneous infrastructure allows organizations to optimize for their specific latency and budget requirements while reducing carbon impact.”
The research highlights practical pathways for AI developers and MLOps teams to build more economical LLM deployments. Through improved understanding of latency requirements developers achieve the best results, leveraging enterprise GPUs for real-time applications with consumer GPUs for development, batch processing, and overflow capacity, organizations can achieve near-H100 performance at a fraction of the cost.
Gaurav Sharma, CEO of io.net, said “This peer-reviewed analysis validates the core thesis behind io.net: that the future of compute will be distributed, heterogeneous, and accessible. By harnessing both datacenter-grade and consumer hardware, we can democratize access to advanced AI infrastructure while making it more sustainable.”
The paper reinforces io.net’s mission to expand global compute capacity through decentralized networks, offering developers programmable access to the world’s largest pool of distributed GPUs.
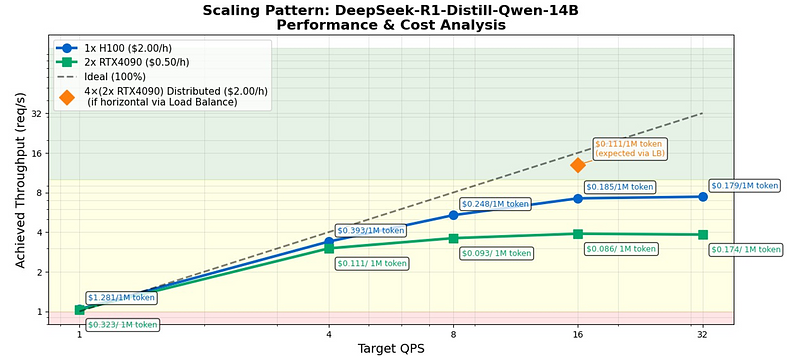
Key highlights include:
- Cost-performance sweet spots:
- 4× RTX 4090 configurations achieve 62-78% of H100 throughput at approximately half the operational cost, with the lowest cost per million tokens ($0.111-0.149).
- Latency boundaries: H100 maintains sub-55ms P99 time-to-first-token even at high loads, while consumer GPU clusters can handle traffic that can tolerate 200–500 ms tail latencies (example: research, dev/test environments, stream chat with respective latency allowed, batch jobs, embedding and eval sweeps).
For more details on the research, please visit the GitHub repository.
Disclaimer: The information in this article is for general purposes only and does not constitute financial advice. The author’s views are personal and may not reflect the views of Chain Affairs. Before making any investment decisions, you should always conduct your own research. Chain Affairs is not responsible for any financial losses.
I’m a crypto enthusiast with a background in finance. I’m fascinated by the potential of crypto to disrupt traditional financial systems. I’m always on the lookout for new and innovative projects in the space. I believe that crypto has the potential to create a more equitable and inclusive financial system.


